前情提要: 昨天我們已經透過get_item將txt裡面的路徑跟label讀進來了,那麼接下來就是要處理data的問題。
接下來我們將音檔load進來,每個音檔的大小當然不一樣,所以我們需要處理一下讓size一樣,之所以要處理是因為,訓練時的Dataloader的batch size絕對不是1,如果不同size的話,他在torch stack時會發生錯誤,後面將給出範例,可以嘗試看看。
所以常見的處理方式:
以上在看訓練時的GPU使用量就會知道,方式一都是固定的,所以GPU使用率會維持一樣,方式二GPU使用率則會忽高忽低的。
以下範例流程為:
修改一下unit_test.txt,讓他實際指到音檔,一樣使用enumerate看一下最後結果。
from torch.utils.data import Dataset
import torchaudio
import torch
import random
class CustomDataset(Dataset):
def __init__(self, txt_path, cut_len = 3 * 16000):
self.data = []
self.get_data(txt_path)
self.label_mapping = {
'ZH': 0,
'EN': 1,
'TW': 2,
'HAK': 3
}
# [Day7]
self.cut_len = cut_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data = self.data[idx]
path, label = data.split('|')
label = self.label_mapping[label]
# [Day7]
audio, _ = torchaudio.load(path)
length = audio.size(-1)
print(f'\nlength: {length}')
if length < self.cut_len:
# case 1: copy
units = self.cut_len // length + 1
audio_3s = torch.cat([audio for _ in range(units)], dim = -1)[:, : self.cut_len]
print(f'copy: {audio_3s.size()}')
# case 2: padding
# pad_len = self.cut_len - length
# audio_3s = torch.nn.functional.pad(audio, (0, pad_len))
else:
# randomly cut 3 seconds segment
wav_start = random.randint(0, length - self.cut_len)
audio_3s = audio[:, wav_start: wav_start + self.cut_len]
print(f'random: {audio_3s.size()}')
return audio_3s, torch.tensor(label)
def get_data(self, txt_path):
with open(txt_path, 'r') as f_i:
lines = f_i.readlines()
self.data = [line.strip() for line in lines]
if __name__ == "__main__":
unit_test = CustomDataset('unit_test.txt')
for idx, (audio_3s, label) in enumerate(unit_test):
print(f'audio_3d: {audio_3s.size()}, label: {label}')
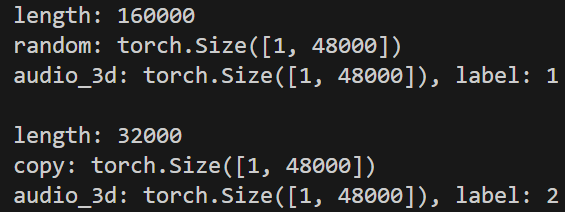
看起來都有達到我們預期的,以下我們多加Dataloader來測試,並看一下正確及錯誤時發生的問題。
from torch.utils.data import Dataset, DataLoader
import torchaudio
import torch
import random
class CustomDataset(Dataset):
def __init__(self, txt_path, cut_len = 3 * 16000):
self.data = []
self.get_data(txt_path)
self.label_mapping = {
'ZH': 0,
'EN': 1,
'TW': 2,
'HAK': 3
}
# [Day7]
self.cut_len = cut_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data = self.data[idx]
path, label = data.split('|')
label = self.label_mapping[label]
# [Day7]
audio, _ = torchaudio.load(path)
length = audio.size(-1)
print(f'\nlength: {length}')
if length < self.cut_len:
# case 1: copy
units = self.cut_len // length + 1
audio_3s = torch.cat([audio for _ in range(units)], dim = -1)[:, : self.cut_len]
print(f'copy: {audio_3s.size()}')
# case 2: padding
# pad_len = self.cut_len - length
# audio_3s = torch.nn.functional.pad(audio, (0, pad_len))
else:
# randomly cut 3 seconds segment
wav_start = random.randint(0, length - self.cut_len)
audio_3s = audio[:, wav_start: wav_start + self.cut_len]
print(f'random: {audio_3s.size()}')
# return audio, torch.tensor(label) # 換成這行就會有error,就是因為size不一樣導致的
return audio_3s, torch.tensor(label)
def get_data(self, txt_path):
with open(txt_path, 'r') as f_i:
lines = f_i.readlines()
self.data = [line.strip() for line in lines]
if __name__ == "__main__":
unit_test = CustomDataset('unit_test.txt')
# for idx, (audio_3s, label) in enumerate(unit_test):
# print(f'audio_3d: {audio_3s.size()}, label: {label}')
# [Day7]
test = DataLoader(
unit_test,
batch_size = 2,
shuffle = False
)
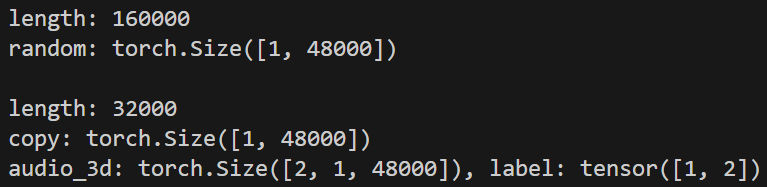
for idx, (audio_3s, label) in enumerate(test):
print(f'audio_3d: {audio_3s.size()}, label: {label}')
我們先看一下正常的會是這樣,可以發現他把兩個[1, 48000]變成了一個[2, 1, 48000],此時你在有些code會看到model那邊會有類似此註解[B, C, T],主要就是此資料的shape,後續會針對model需求去reshape等等。
B: Batch Size
C: Channel
T: Time
那我們來看一下錯誤的時候會發生什麼,會跑了一長串的error,最下面會發現它執行torch.stack的時候預期要一樣的size,這樣子應該就可以理解為什麼size要處理成一樣了吧!!

補充: torch stack是dataloader程式當中預設用這個方式幫你處理的,你也可以自行設計。
今天大致上已經完成一個最基礎的Dataset,自己實作過後,看別人的程式應該就會清楚很多。
沒想到持續更新7天了QQ,希望這系列能幫助到你~~


 iThome鐵人賽
iThome鐵人賽